About the customer
Vakko, Turkey’s leading fashion house and luxury goods brand, started out as a small hat shop called Şen Şapka (Merry Hats). Founded by Vitali Hakko in 1934, Şen Şapka soon became the Vakko brand, producing scarves made of Turkish silk based on the latest fashions. Inspired by the mood of development and innovation in the country at the time, Vakko recognized the need to expand beyond hats, scarves and printed fabrics and ventured into the ready-to-wear industry, where the company has been a sector leader ever since. Vakko’s primary goal has been to create collections that interpret the latest fashions, while offering superior quality, exquisite craftsmanship and excellent service.
Today, Vakko specializes in high-fashion luxury goods through its numerous collections and stores: Vakko Scarves, Vakko Men and Vakko Women, Vakko Couture, V2K Designers, Vakko Wedding, Vakkorama concept stores, W Collection Menswear and Vakko Home. Vakko also brings its high quality to the gourmet food sector with Vakko Chocolate, Vakko Tea Atelier, Vakko Coffee Atelier, as well as the high-end patisserie concept Vakko Patisserie Petit Four, and French restaurant Vakko Bistrot.
Business challenge
The goal was to develop Vakko’s data lake to collect data from various internal and e-commerce web applications in a central data store, make analyses of the data, run machine learning algorithms for predictions, and share 360-degree customer business intelligence data internally with other applications and with partners for personalized e-marketing, product catalog integration, order delivery, CRM integration, etc.
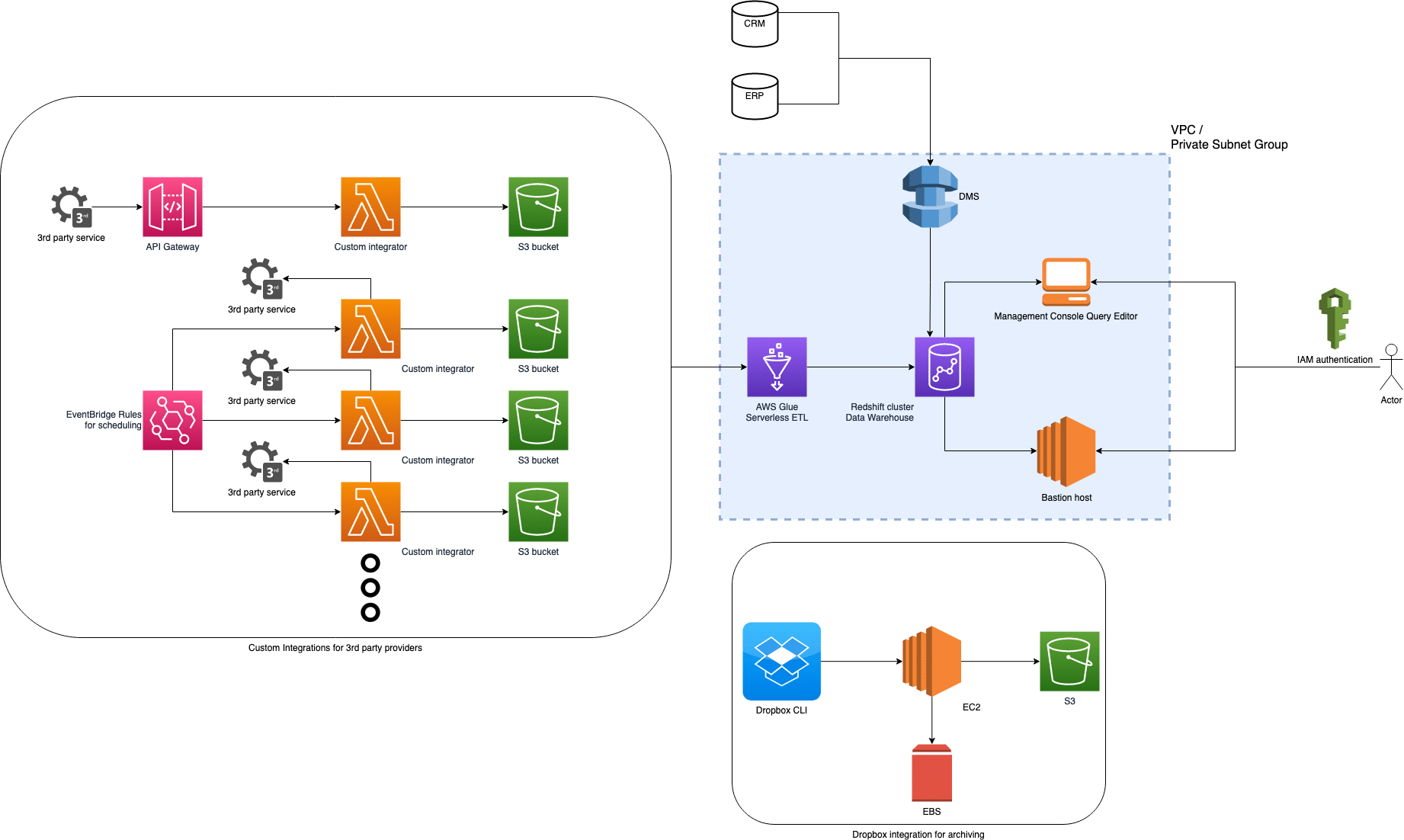
The source data was in different mostly on-prem databases with various formats. Additionally, Vakko’s application infrastructure had integrations with third party services for its daily operations. By leveraging the data related services of AWS such as Database Migration Service for replication, Glue for serverless ETL pipelines, a completely automated ETL pipeline for data collection and analysis was set up. After consolidating all data in a centralized data store, it can now be queried, and reported by internal users and external partners with various synchronous and asynchronous integrations.
Solution
Commencis Cloud Team developed integrations for third party services, implemented and automated ETL pipelines for a ready to-use data analytics platform.
Various integrations were developed using Lambda functions and automated by EventBridge rules. Gathered data was saved in raw format into S3 buckets, acting as a data lake. The raw data was then processed by the serverless ETL tool, Glue, to be ready to run analytical queries. Analytical queries were developed by Vakko and automated by Commencis.
Transfer of Data from Databases: Vakko also uses legacy database systems containing CRM and ERP data. Data in these services is also transferred into the data warehouse as is, using DMS’ full snapshot and ongoing replication features.
Integration of Third-Party Services with Lambda: For integration with 3rd party services Vakko uses for various business purposes (such as: logistics, customer interaction, online marketplaces…) Lambda functions are developed. These functions connect to their respective services and collect data for saving in the data lake. This collected data is then preprocessed and inserted into the data warehouse layer (Redshift) by using automated Glue crawlers and jobs.
- biotekno_daily
- ups_daily
- akinon_daily
- vcount_daily
- trendyol_daily
- yurtici_daily
The pandas package contains 6 functions that share the same layer for basic data preprocessing operations. Lambda functions are named after service providers and the period during which data is collected. These functions are triggered by an EventBridge rule to collect data from the previous day, transform into the required format, and finally save it into S3 buckets.
Sorun_hook is another Lambda function developed as a webhook, connected to API Gateway, and triggered by messaging application providers. In case of an updated message, the client sends a request to the specified endpoint. Lambda function handles the request body, in a similar manner to other 3rd party integrations.
Dropbox Integration: As a custom request to safely archive commonly shared content, Dropbox to S3 integration has been provided for Vakko. While there are multiple 3rd party solutions for Dropbox to S3 synchronization, an in-house solution was preferred. Dropbox is continuously synchronized with EBS and S3 using an EC2 instance with enough EBS space.
Querying and Reporting Consolidated Data: The data collected in Redshift has been made accessible from internal and external systems with strict security checks. In addition to online access to Redshift data, it is filtered and exported to S3, to be able to share it with external parties as offline integrations.
Use of third-party applications or solutions
Oracle Database: Vakko uses legacy Oracle databases for their ERP and CRM solutions. These legacy databases are migrated to AWS Redshift for analytical purposes using AWS Database Migration Service.
Dropbox: Dropbox is used by Vakko as a common file sharing platform. A Dropbox to S3 integration is developed to archive content.
Gerrit: Gerrit is a source control management and code review tool that uses git. Source codes for developed Lambda functions are managed over Commencis’ self-hosted Gerrit instances.
Jenkins: Jenkins is used for deployment of Lambda functions, again hosted on Commencis’ servers
AWS Services used as part of the solution
AWS Glue: Used as ETL tool
AWS DMS: Migration from legacy CRM, ERP databases is done with the use of DMS.
AWS Lambda: Lambda functions are developed using Python with panda’s library to acquire and efficiently save the data.
Amazon Redshift: A powerful Redshift cluster is set up to meet Vakko’s data analysis purposes.
S3: S3 is used for storing raw data.
EC2 & EBS: Is used for an intermediate device for Dropbox synchronization to S3
API Gateway: is used for providing a secure webhook for a 3rd party service integration.
Architecture diagram of solution deployment
Most integrations were completed by leveraging Lambda functions. These are used as a serverless preprocessing tool that can easily be maintained and automatized. Other data sources are continuously copied into the data warehouse using the ongoing replication functionality of DMS.
Outcomes & Benefits
Vakko now has a “customer 360-degree” (customer analytics) data warehouse system integrated with various external third party and internal applications. This data warehouse is developed by Lambda functions, Glue ETL pipelines and DMS replication services.
The product information data store can be queried concurrently by many external systems. Moreover, it is deployed in AWS on a highly scalable and high-performance architecture.
Client Case Studies
We deliver solutions using our extensive knowledge and more than 10 years of cloud transformation experience.

BSH
BSH, one of the world's leading home appliance manufacturers, aimed to develop PIM (Product Information Management) processes that would allow end users to…

Akinon
Boosting e-Commerce capabilities through new flexible and secure infrastructure

PayCore
Thanks to close cooperation between cloud and engineering teams of Commencis, PayCore managed to deploy their new application release by using the CI/CD…

Binnaz
Commencis brought DevOps best practices to Binnaz by fully integrating development and operations.

Faladdin
Faladdin modernizes for enhanced performance with DevOps help from Commencis