Commencis Introducesits Purpose-Built,Turkish-Fluent LLMfor the Banking andFinance Industry
— A Detailed Overview
Generative Artificial Intelligence (AI), particularly through the advancements in large language models (LLM), is quickly becoming essential in various industries, significantly enhancing customer experience. It powers chatbots and virtual assistants for real-time interactions, personalizes recommendations, enables targeted marketing, and offers advanced voice and image recognition. Additionally, sentiment analysis, bolstered by the sophisticated understanding capabilities of large language models, helps understand customer feelings, making services more responsive and tailored. This technology is reshaping how businesses connect with customers, providing efficient and personalized solutions through their digital channels.
By 2027, chatbots will become the primary customer service channel for roughly a quarter of organizations, according to Gartner, Inc. [1] Organizations that integrate chatbots and assistants to their digital businesses in the most ‘agent-like’ form; will have a competitive advantage for sure.
As a leading tech company accelerating the digital transformation of large enterprises, we introduce Commencis LLM, a Turkish-specific large language model developed for various industries, notably banking and finance.
This model is engineered to enhance efficiency across pivotal functions such as customer service, content creation, and data analysis, precisely addressing the specialized needs of the banking and finance landscape.
While its immediate focus is on banking and finance, Commencis LLM’s technical approach makes it capable of improving user experiences in other sectors such as airlines, insurance, e-commerce, and telecommunications. This approach aims to significantly advance digital channel customer interaction.
Embracing Exploration and Experimentation
The development of the Commencis LLM began with an in-depth literature review and comprehensive analysis of existing large language models. Our journey into the field of AI started by experimenting with leading models such as Llama 2, Mistral, Mixtral, Zephyr, and OpenChat 3.5, from which we derived critical insights such as base models’ behaviors; that shaped our approach. This exploratory phase not only enriched our understanding but also guided the data collection, preparation, and filtering processes crucial for the next stages of development.
The project required substantial computational resources, prompting us to utilize Amazon Web Services’ high-performance GPUs, specifically the g5.2xlarge and g5.48xlarge instances. These powerful machines provided the necessary firepower for our intensive tasks, from handling vast amounts of data to the demanding process of training our model. The g5.2xlarge instances supported our significant resource needs, while the g5.48xlarge instances were deployed for the most resource-intensive operations.
Over three months of intensive work, the engineering team at Commencis dedicated themselves to fine-tuning the LLM. This period was marked by a dedicated effort to refine the model’s understanding of Turkish and its ability to capture semantic relationships more accurately than ever before.
Utilizing AWS’s G5 instances allowed us to optimize the training process, ensuring that our model had access to the resources it needed to unlock its full potential. The culmination of these efforts was a chat model skilled at answering questions across various domains, responding to user commands, and catering to requests with a deep understanding of the Turkish language.
Selecting the Base Model
Exploring multiple base models was crucial when selecting the optimal base model for two reasons:
- The Chatbot Arena Leaderboard [2] is the go-to place to monitor the crowdsourced evaluation platform that ranks LLMs specifically for chat-focused applications. However, while a model’s ranking provides significant insights into its overall performance, it does not account for specific criteria such as fluency in the Turkish language and adaptability to training and fine-tuning.
- The arena is constantly evolving. Although we have chosen a base model that suits our needs at this stage of our exploration, this selection is provisional. The correct training and dataset strategy can be effective across most base models.
For the foundational architecture of Commencis LLM, Mistral 7B was strategically chosen as the base model, distinguishing itself from other candidates through its exemplary performance on diverse datasets and its adeptness at mastering a language like Turkish with which it has limited familiarity.
Pre-trained with an impressive 7 billion parameters, Mistral 7B appeared as the ideal candidate for processing and training on the intricate and specialized textual data within the banking and finance industries. Its proven capacity to handle complex datasets and specific terminologies made it an invaluable asset in our quest to develop a language model that not only understood Turkish with great proficiency but also possessed the sophisticated understanding necessary for applications in the banking and finance domain.
Preparing and Refining Datasets
In the development of Commencis LLM, our team embarked on a comprehensive journey to construct a customized dataset specifically designed to bolster the model’s ability in Turkish, particularly for the banking and finance industry. This process began with an extensive collection of diverse data types, including customer service records, financial reports, market analyses, and legal and regulatory documents, all vital for the model to grasp the unique jargon, terminology, and expressions of the industry.
A comprehensive data cleaning and organization phase was undertaken, during which low-quality and irrelevant data were removed. To ensure linguistic diversity and enhance the model’s processing capabilities, efforts were made to balance data from various language structures. Additionally, considerations such as gender, ethnicity, and geographical location were incorporated to reduce bias and increase the diversity of responses. Faced with the challenge of a scarcity of Turkish language datasets for pre-trained open-source large language models, especially in the banking sector, a strategic initiative was launched. This initiative aimed not only to collect and curate existing data but also to generate new datasets that could provide a deeper understanding of Turkish and banking-related terminologies. Various methods to create data specifically for the banking industry were investigated. By leveraging terms from the banking and finance glossary and the relationships between defined categories and sub-categories, OpenAI’s GPT-4 services were utilized to produce thousands of synthetic instructions aimed at generating data suitable for supervised fine-tuning training. These synthetic instructions played a pivotal role in fine-tuning the models, contributing to setting a new standard for the preparation and testing phases. Here is a detailed overview of all the datasets employed in this endeavor:
- Enhanced CulturaX Dataset [3] with Refined Data:
Description: Curated from a multitude of sources on CulturaX, this dataset is designed to provide a comprehensive foundation in the Turkish language, covering a broad spectrum of texts to encapsulate the language’s intricacies.
Entries: 11,453
Purpose: To serve as the initial training dataset, offering a wide-ranging understanding of Turkish.
- Turkish Version of the Alpaca Finance Dataset [4] (Translated):
Description: An enhanced translation of the Alpaca Finance dataset into Turkish, aimed at localizing the content for Turkish-speaking users.
Entries: 42,438
Purpose: To ensure the availability of finance-specific content in Turkish, catering to the needs of local users and professionals in the banking sector.
- Synthetically Generated Dataset for Banking Sub-Domains:
Description: This dataset is created synthetically to cover various banking sub-domains, ensuring a thorough representation of the sector’s diversity.
Entries: 7,450
Purpose: To deepen the model’s understanding of niche areas within banking and finance.
- Synthetic Banking Instructions Derived from a Comprehensive Dictionary Dataset:
Description: Utilizing a comprehensive dictionary as its foundation, this dataset provides synthetic banking instructions, aiming to simulate real-world financial interactions.
Entries: 8,300
Purpose: To train the model on the specific language used in banking instructions and operations.
- Turkish Financial Question and Answer Dataset:
Description: Comprising a series of questions and answers related to finance, this dataset is designed to enhance the model’s ability to engage in interactive financial discussions in Turkish.
Entries:429
Purpose: To improve the model’s conversational capabilities in financial contexts, facilitating accurate and informative exchanges.
These datasets collectively form a robust foundation for training language models that are not only proficient in Turkish but also deeply versed in the banking and finance domain. In addition to the focus on banking-specific content, a huge portion of the datasets also encompasses general-use question and answer pairs, aiming to enhance the models’ versatility across various conversational contexts.
This comprehensive approach, which includes the creation of synthetic datasets and the specialized translation of existing materials, underscores a commitment to addressing the unique challenges and requirements of the Turkish market. This strategy ensures that the models can handle various applications, extending their usefulness beyond finance to support users in diverse conversations.
Throughout the development of Commencis LLM, commitment to quality was a top priority. A specialized filtering method was introduced to elevate the quality of question-answer interactions, with the data’s Turkish ability, accuracy, clarity, and scope thoroughly evaluated using GPT-4. This strategic removal of data not meeting our strict quality benchmarks significantly enhanced the training dataset’s quality, thus substantially improving the model’s ability to understand and respond in Turkish.
This detail-oriented approach not only addressed the critical gap in Turkish datasets but also established a solid foundation for Commencis LLM to effectively meet the specific needs of the banking and finance industries, leveraging AI technologies for improved language understanding and interaction.
Analyzing Training Results
In the aftermath of the fine-tuning phase, a sophisticated scoring system inspired by Zheng et al.’s “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” article was utilized [2], taking advantage of GPT-4’s advanced capabilities to assess and enhance our models’ performance.
This innovative system scrutinizes the models across five crucial metrics: Turkish language proficiency, relevance, correctness, conciseness, and completeness of responses. These metrics serve as the cornerstone for implementing necessary adjustments to datasets and fine-tuning parameters, significantly enhancing the models’ ability to communicate in Turkish and cater to specific user needs effectively.
To systematically assess the models, particularly those pretrained or fine-tuned for the Turkish language, we developed a comprehensive framework. This framework is designed to evaluate models against the complex requirements of the Turkish language and user inquiries, focusing on:
- Turkish Language Proficiency: Gauging the models’ grasp of Turkish, this criterion examines their capability to understand and accurately respond to queries, considering grammar, vocabulary, and the subtleties of linguistic context.
- Relevance: Assessing the alignment of the models’ responses with the specific questions posed by users, ensuring the information provided is directly relevant and devoid of irrelevant content.
- Correctness: Evaluating the factual accuracy of responses, which should be grounded in reliable data or procedures that reflect the context of the user’s request accurately.
- Conciseness: Considering the brevity of responses, this metric emphasizes the importance of delivering the necessary information efficiently, without superfluous details.
- Completeness: Ensuring responses comprehensively address all aspects of the user’s inquiry, offering detailed explanations or guidance that may pre-empt follow-up questions.
Incorporating these criteria into our evaluation process, coupled with an average rating system, allows for a thorough assessment of the models’ capabilities in Turkish. This structured approach not only enhances the effectiveness and efficiency of language models in processing and responding to Turkish inquiries but also highlights our commitment to developing AI technologies that meet the evolving needs of users with precision and reliability.
Evaluating Outcomes
The model was evaluated using a randomly selected test set of 195 questions focused on information retrieval for the banking and finance domain. In the Appendix, a selection of the posed questions and the responses provided by the model can be found.
Based on the evaluation results, the performance of the Commencis LLM model and that of both open-source base models (Llama 2 7B, Mistral 7B, Mixtral 8x7B) and GPT models (GPT 3.5 Turbo, GPT 4 Turbo) is illustrated in the radar chart and the table below.
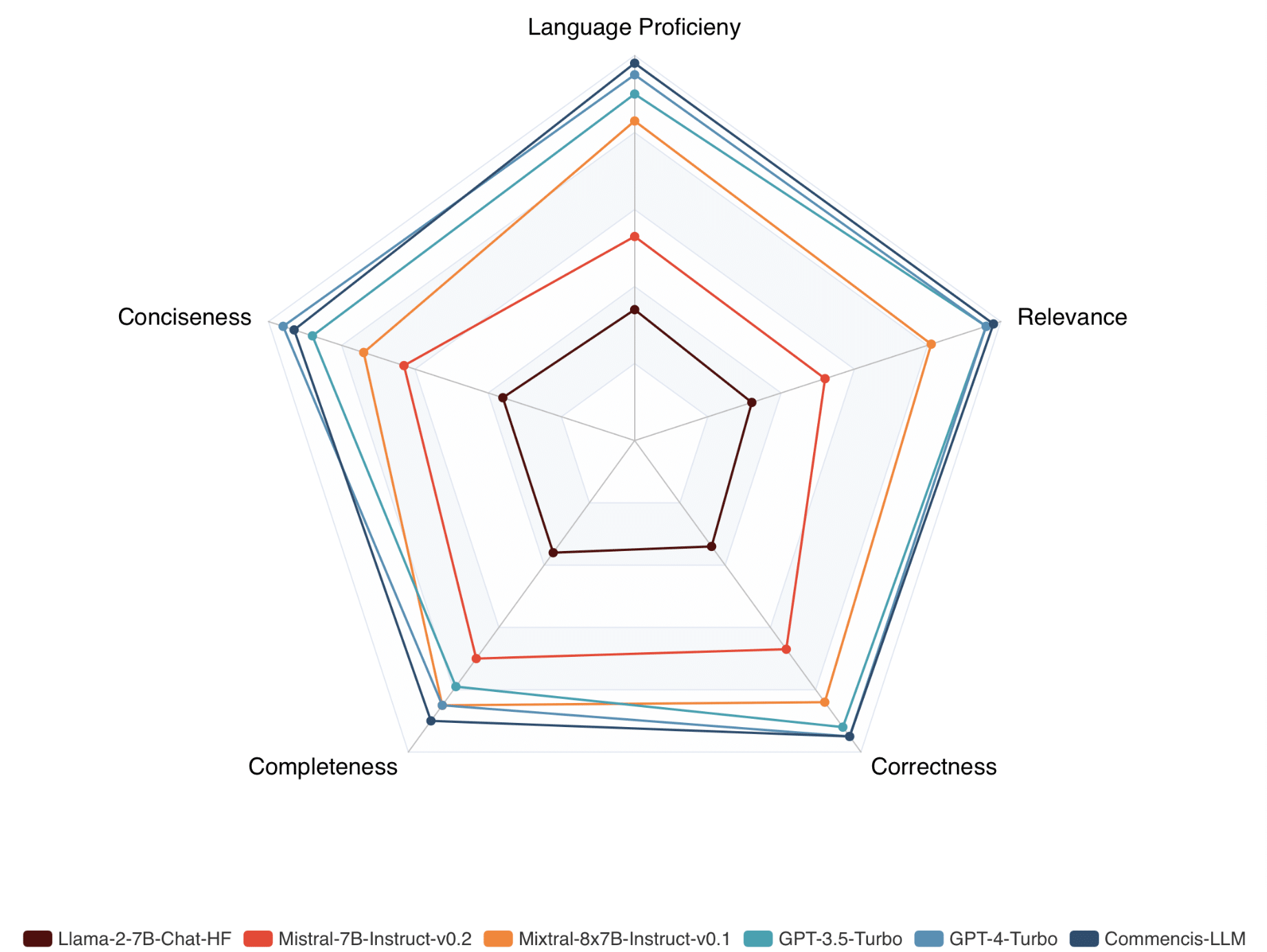

In an in-depth comparison of the Commencis LLM against other models across five critical performance metrics, Commencis LLM distinguishes itself as a leading solution in the banking and finance sector, especially within the Turkish language context. Here’s a concise summary of its standout performance:
- Turkish Language Proficiency: Commencis LLM achieves a remarkable score of 9.8, surpassing competitors with its exceptional command of the Turkish language, particularly in technical banking and finance terminologies, ensuring highly accurate and contextually relevant responses.
- Relevance: With a top score of 9.8, it demonstrates unparalleled ability to identify and respond with information directly relevant to users’ queries, an essential attribute in the fast-paced finance sector.
- Correctness: Matching GPT-4 Turbo with a score of 9.5, it shows exceptional accuracy, delivering reliable and correct information critical for financial decision-making.
- Completeness: Achieving a score of 9.0, Commencis LLM excels in providing comprehensive answers to complex queries, offering a depth of understanding unmatched by many competitors.
- Conciseness: Scoring 9.3, it efficiently distills complex financial data into clear, straightforward responses, essential for rapid decision-making.
Overall, Commencis LLM’s superior performance underscores its exceptional suitability for the banking and finance domain, offering precise, accurate, and richly contextual responses. It stands out not only for its domain-specific capabilities but also for its deployability on-premise, a crucial factor for industries prioritizing data sovereignty, privacy, and security.
In comparison, GPT-4 Turbo’s commendable performance as a general-purpose model highlights the versatility of such models. However, the inability to deploy GPT-4 Turbo on-premise poses significant challenges for sectors like banking, where data privacy and security are paramount.
It is also noteworthy to appreciate the performance of GPT-4 Turbo, a general-purpose model, within this context. Despite the specialized nature of banking and finance where Commencis LLM is explicitly fine-tuned, GPT-4 Turbo’s close performance is commendable. This observation hints at the incredible versatility and adaptability of general-purpose models. While our decision to narrow down to the banking and finance domain might introduce a bias favoring the specialized Commencis LLM, it does not detract from the impressive capabilities of GPT-4. Rather, it highlights the importance and potential advantages of specialized models in meeting specific industry needs without undermining the broad applicability of more generalized solutions.
In conclusion, the customized, on-premise deployment of specialized models like Commencis LLM presents a significant advantage, ensuring compliance and data control within the sensitive framework of the banking and finance industry. This approach not only addresses privacy and security but also aligns with the technical and regulatory complexities of the sector, demonstrating the necessity and benefits of specialized models in meeting industry-specific demands.
Envisioning Next Steps
Commencis is making remarkable progress with its innovative focus on large language models, notably through the creation of the Commencis LLM. This initiative is pivotal in transforming digital interactions in sectors such as banking and airlines, highlighting the crucial role of large language models in refining customer service, content creation, and data analysis. With a focused blend of AI and dedicated experimentation, including leveraging AWS for its computing capability, Commencis tackles the challenge of expanding Turkish language model ability amid limited dataset availability.
Our approach is not just about pushing the boundaries of large language model capabilities but also addressing real world challenges through AI, setting a new benchmark in the industry. By offering seamless digital assistant experiences, we aim to simplify everyday tasks for users across digital channels.
Recognizing the importance of data security, especially with the constraints of the Personal Data Protection Law (KVKK), Commencis designed an on-premise platform to build assistants and integrate to digital channels while providing access to its extensive repository of fine-tuned language models via its dedicated Hugging Face page. The LLM is available as open source, and access to a sample finetuning dataset can also be obtained at the platform.
This initiative not only underlines the commitment of Commencis to innovation and excellence in the field of AI but also paves the way for a future where digital assistants vastly improve our daily digital interactions.
Citation
[1] Gartner, Inc. “Gartner Predicts Chatbots Will Become a Primary Customer Service Channel Within Five Years.” Available at: https://www.gartner.com/en/newsroom/press-releases/2022-07-27-gartner-predicts-chatbots-will-become-a-primary-customer-service-channel-within-five-years.
[2] “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.” ArXiv, https://arxiv.org/abs/2306.05685.
[3] “CulturaX Dataset.” Hugging Face, https://huggingface.co/datasets/uonlp/CulturaX.
[4] “Alpaca Finance Dataset.” Hugging Face, https://huggingface.co/datasets/gbharti/finance-alpaca.
Appendix
Tahvil getirisi nasıl hesaplanır?
Tahvil getirisi, tahvilin nominal değeriyle vade sonunda ödenen tutar arasındaki farkın yüzdeye çevrilmesiyle hesaplanır. Örneğin, bir tahvilin getirisi %5, birinin ödediği tahvilin nominal değeri 1000 TL ve vade sonunda ödenecek olan tutar 1050 TL ise, getirinin hesaplanması şöyle olacaktır: (1050 TL – 1000 TL) / 1000 TL = %5.
Kredi kartı limiti nasıl artırılır?
Kredi kartı limitinizi artırmak için bankanızın müşteri hizmetleriyle iletişime geçebilirsiniz. Limit artırım talebinizi iletebilir ve gerekli belgeleri sunabilirsiniz. Banka, talebinizi değerlendirecek ve size geri dönüş yapacaktır. Limit artırım talebinizi hızlandırmak için düzenli olarak kredi kartı ödemelerinizi yapmanız da önemlidir.
Banka kartının günlük alışveriş limiti nasıl artırılır?
Banka kartınızın günlük alışveriş limitini artırmak için bankanızın müşteri hizmetleriyle iletişime geçebilirsiniz. Limit artırım talebinizi iletebilir ve gerekli prosedürleri takip edebilirsiniz.
Yatırım fonu nedir ve nasıl alınır?
Bir yatırım fonu, birden fazla yatırımcının paralarını bir araya getirerek profesyonel bir fon yöneticisi tarafından yönetilen bir yatırım aracıdır. Yatırım fonları, hisse senetleri, tahviller, emtia ve diğer finansal araçlar gibi çeşitli varlıklara yatırım yapabilirler. Yatırım fonlarını almak için genellikle bir yatırım fonu yöneticisinden veya bir yatırım platformu aracılığıyla yatırım yapmanız gerekmektedir. Yatırım fonları, genellikle hisse senetleri borsaları veya diğer finansal platformlar aracılığıyla alınır.
Vadeli mevduat faizi nasıl belirlenir?
Vadeli mevduat faizi genellikle yatırımın tutulma süresine ve ana paranın tutulma süresine bağlı olarak belirlenir. Bankaların sunduğu faiz oranları da faizi etkiler.
Faiz oranları nasıl belirlenir?
Faiz oranları, piyasadaki arz ve talep, para arzı, enflasyon oranları ve merkez bankası politikaları gibi faktörlere göre belirlenir.
Faktoring nedir?
Faktoring, bir işletmenin alacaklarını bir faktoring şirketine satmasıdır. Bu, işletmenin nakit akışını iyileştirir ve alacak riskini azaltır. Faktoring şirketi, alacakları peşin alır ve işletmeye belirli bir miktar para öder.
Forfaiting nedir?
Forfaiting, bir ihracatçının alıcı bulmak zorunda kaldığında alıcının ödeme yapmaması riskine karşı korunmasını sağlayan bir finansman yöntemidir. Forfaiting şirketi, ihracatçının alıcının ödeme yapmaması riskini üstlenir ve ödeme yapılmadığında ihracatçıya belirli bir miktarı geri öder. Bu, ihracatçının nakit akışını sağlar ve riskini yönetir.
FAQ
Commencis LLM is a custom-built large language model designed to understand and generate Turkish with high accuracy, specifically for the banking and finance industry. It helps financial institutions automate support, streamline compliance, and generate domain-specific content securely.
Off-the-shelf AI models often lack Turkish language fluency and domain accuracy. Commencis developed this LLM to meet the sector’s unique linguistic, regulatory, and data privacy needs—delivering precise responses in Turkish, tailored to financial terminology.
Commencis LLM is fine-tuned from the Mistral 7B base model, selected for its strong performance and flexibility. It was trained on real and synthetic Turkish finance datasets, including banking documents, regulatory texts, and conversational prompts.
It powers secure, on-premise applications like AI assistants, customer service bots, document summarization tools, and internal search systems. It ensures faster, more accurate information retrieval—all while keeping sensitive data within the bank’s infrastructure.
The model was tested across metrics like fluency, factuality, relevance, and completeness using finance-specific prompts. It consistently outperformed general-purpose models in understanding and responding to Turkish banking queries.
Yes. While optimized for finance, Commencis LLM’s architecture is adaptable for other regulated industries such as insurance, telecom, and travel-anywhere. Domain-specific language and local language fluency are critical.
Reading Time: 12 minutes
Don’t miss out the latestCommencis Thoughts and News.
